Although there has been a proliferation of biological datasets made available in recent years, often this information isn’t machine readable, making it hard for things like Google Dataset Search to find and index them. In this series of blog posts, we’ll outline how we are working to make datasets that our collaborators generate and open data more findable, accessible, interoperable, and reusable, as well as tools that we’ve developed to make it easier to share data. In this post we introduce the schema playground in the Data Discovery Engine and how to use it.
What is the Data Discovery Engine, and how can it help you leverage schemas?
The schema playground in the Data Discovery Engine allows you to create a new schema (or data type) from existing schemas. Schemas generated with the Data Discovery Engine are schema.org-compliant so that search engines will know how to interpret them, and they are presented in an easy-to-use interface. (For more about schemas, check out our previous post)
When you first visit the schema playground in the Data Discovery Engine, you’ll see that there are three ways to get started on creating or using a schema.
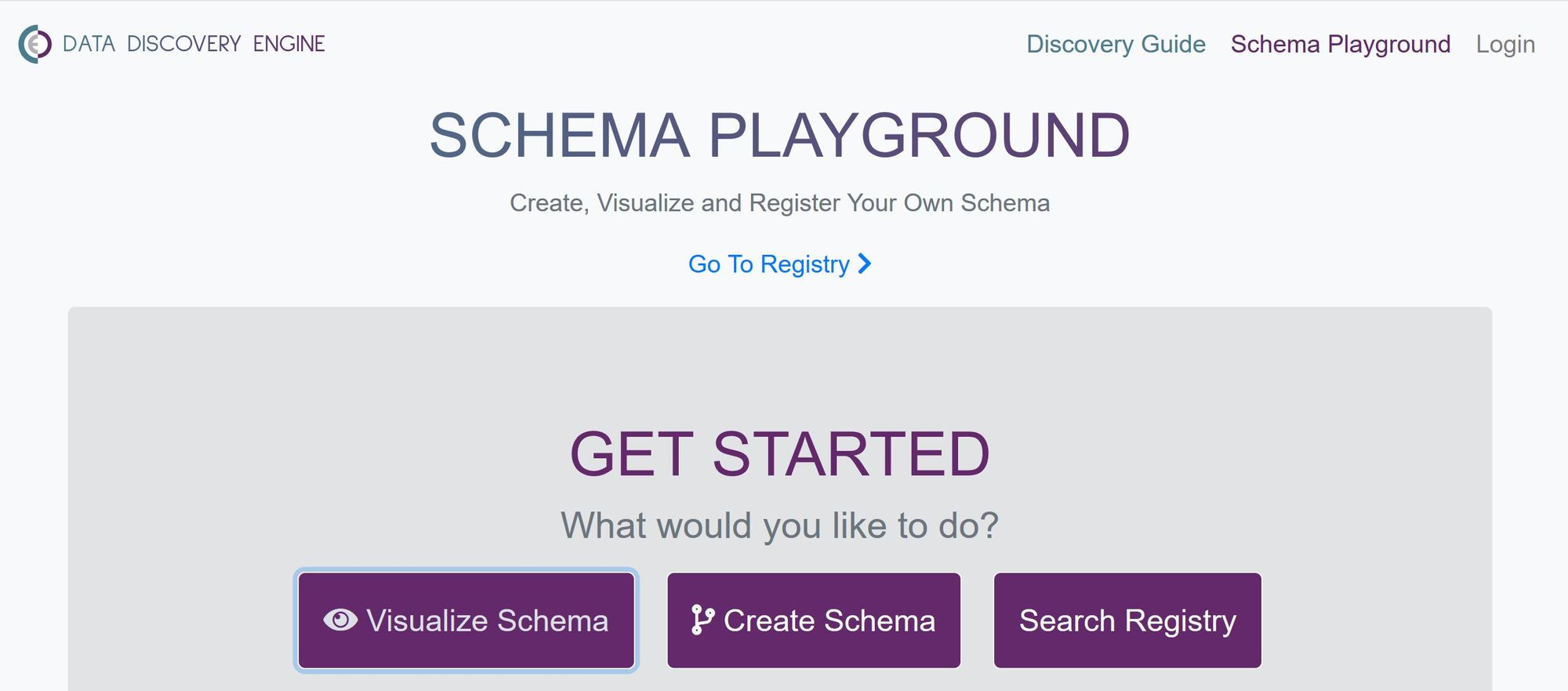
If you have worked with schemas before and are familiar with them–you may prefer to just create them on your own. In this case, you would select the first option, ‘visualize schema’. This option allows you to visualize a pre-existing schema as long as the raw .json is available online. This includes .json schema files in repositories like GitHub.
The visualize schema function is handy for identifying errors in your schema and will help check to ensure your schema is valid. It includes a built-in json schema validator, just like other json-schema validators like the Json schema validator; only it will allow you easily visualize your schema AFTER your schema has been found to be valid.
That is, if you visualize a valid schema, you will be able to easily view the schema, related schemas, and properties.
On the complete other hand, if you don’t want anything to do with the creation of a schema, you can try searching the schema registry (the ‘search registry’ option) for a pre-existing schema to use. Schemas that are created and registered by other people to suit their specific needs are included as well as all schemas from schema.org. Before you go through the effort of creating a schema, we recommend that you search the registry to see if one that suits your needs already exists and save yourself the effort. Using a pre-existing schema has the added benefit of helping to standardize the use of that schema.
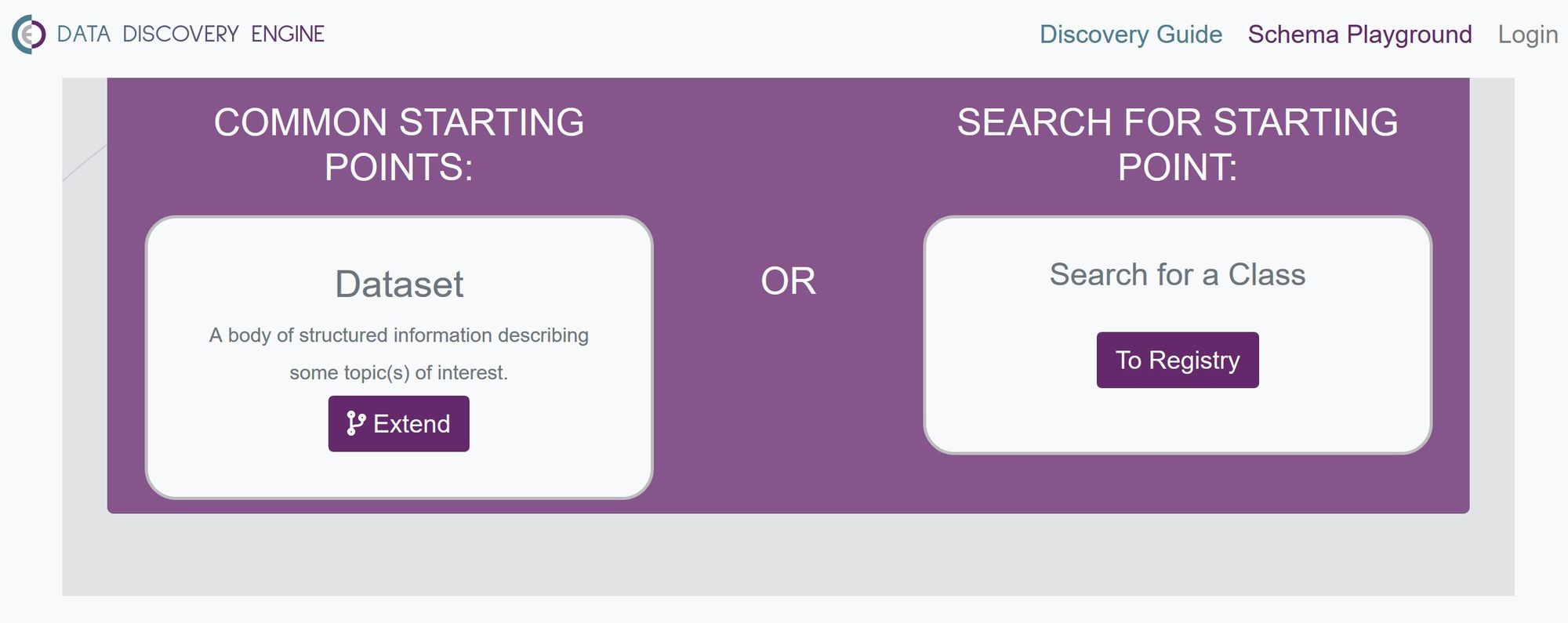
If you’re unable to find a schema that suits your needs, you can use the middle option (‘create schema’) to create a new schema by extending/manipulating a pre-existing schema. In this case, you would find a schema that most closely resembles what you need, and then extend it to fit your needs.
Note that some parts of the schema playground in the Data Discovery Engine require a login to proceed. The login requirements can be satisfied using your github credentials.
Once you’ve successfully created a valid schema, you are encouraged to register it. When you register a schema, you share your schema allowing other researchers with similar data to use your schema. This helps to improve metadata standardization, interoperability, findability, and reuse.
To share datasets on Ebola and Lassa Fever created by the Center for Viral Systems Biology, we developed a general biological Dataset schema using the Data Discovery Engine. Working off of the schema.org Dataset schema, we identified a small subset of properties that we thought are essential to describe a dataset, and added properties that are unique to infectious disease research, like infectiousAgent. Working off of the existing schema.org framework both saved us time and allows these datasets to be compliant with data sharing projects like Google Dataset Search.
Since this Dataset schema was registered and shared, when the COVID-19 pandemic started, the Outbreak.info team was able to quickly adapt it to provide a standardized searchable interface of COVID-19 resources. In addition to recycling the Dataset schema we already developed, we identified a number of pre-existing schemas to adapt and modify to cover additional resource types. We expanded this NIAID Dataset schema to also harmonize Analyses, Publications, Clinical Trials, and Protocols from disparate sources. Having these schemas meant that the metadata for these resources could be parsed, normalized, and made more findable for search engines. The resulting schema can be used as the basis for other projects as well.
Now that we’ve invested so much time in creating standardized metadata to describe datasets and other resources, the next step is to easily access all this information. If you’re a researcher, sometimes you’d prefer to access information in bulk–and for that you’d need an Application Programmable Interface (or API).
Fortunately, for the Outbreak.info team, the Wu and Su labs have a lot of experience building APIs and already have a tool available for spinning up RESTful APIs quickly: The BioThings Software Development Kit (SDK). In the next post, we’ll describe how we used these tools to quickly create an API to access metadata on COVID-19 resources.